- Published on
The 1 Million Token Context Window: A Game Changer or a Computational Challenge?
- Authors

- Name
- AIFlection
The 1 Million Token Context Window: A Game Changer or a Computational Challenge?
Introduction
In 2024, I deployed three large-scale LLM applications into production, and every time, I found myself thinking, If only I had a larger context window, many of my challenges would be solved. Short context windows often led to loss of crucial information, requiring complex retrieval mechanisms to reconstruct missing context. Debugging long conversations, handling multi-step reasoning, and processing large documents were some of the most frustrating limitations I faced.
With Google’s recent announcement of Gemini 1.5 and its 1 million token context window, it seemed like my wish was finally coming true. But then, I asked myself: Is it really all good? Or are there hidden downsides to a 1M token window?
After spending some time diving deep into this topic, evaluating both its potential and pitfalls, I decided to write this blog to share insights that could benefit AI practitioners, researchers, and industry leaders alike.
Advantages of a 1M Token Context Window
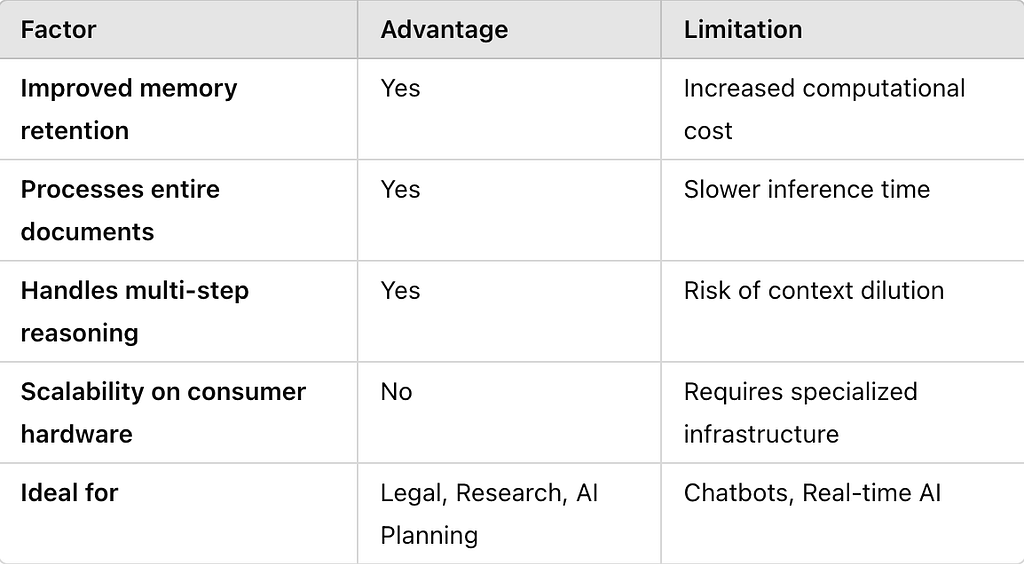
1. Eliminates Chunking & Retrieval Issues (Debatable)
Traditional models struggle with retrieving relevant information from long documents due to context size limitations. With a 1M token window, entire books, research papers, or codebases can be processed in one go, eliminating the need for complex retrieval-augmented generation (RAG) techniques.
Example Application: Legal AI systems can process entire contracts without requiring document segmentation.
2. Improved Long-Term Context Retention
Many current AI models forget earlier parts of a conversation due to limited context size. With an expanded window, models can maintain memory over longer interactions, leading to improved continuity in responses.
Example Application: AI-powered personal assistants that retain conversational context over extended periods.
3. Enhanced Multi-Step Reasoning and Planning
With a longer memory, AI can track complex workflows, dependencies in large codebases, and multi-step financial analysis without losing critical context.
Example Application: AI-driven financial analysis tools can evaluate multi-year financial reports without requiring frequent context resets.
4. Improved Storytelling and Content Generation
AI-generated content often struggles with consistency in long narratives due to context limitations. A 1M token window enables more coherent and structured content over extended text.
Example Application: AI-assisted novel writing tools that maintain character development and plot consistency over longer narratives.
Challenges and Limitations
1. High Computational Cost
Transformers scale quadratically with sequence length, significantly increasing memory and computational requirements. Running 1M tokens requires high-end GPUs such as A100, H100, or TPUs, making it inaccessible for general users.
Example Issue: Consumer-grade hardware (e.g., RTX 4090) struggles beyond 32K tokens, making large context sizes impractical for widespread use.
2. Slower Inference Time
Even with optimized attention mechanisms such as FlashAttention, processing 1M tokens is resource-intensive and slows down real-time response generation.
Example Issue: AI chatbots with 1M token context may experience increased latency, affecting usability in real-time applications.
3. Context Dilution and Relevance Filtering (My Biggest Concern)
A larger context does not guarantee improved accuracy. The model must still identify the most relevant information within 1M tokens, increasing the risk of retrieving non-essential data.
Example Issue: If an AI model is tasked with summarizing Chapter 5 of a book, it may struggle to efficiently pinpoint the relevant content amidst excessive information.
4. Limited Practical “Real World” Applications
Many real-world applications do not require a 1M token window. More effective retrieval methods can achieve similar outcomes without the need for extreme context sizes.
Example Issue: Customer support chatbots benefit more from improved retrieval mechanisms rather than storing an entire knowledge base within a single prompt.
Ideal Use Cases for a 1M Token Context Window
Effective Applications
- Legal and Compliance AI: Can process full legal contracts and regulatory documents without segmentation.
- Scientific Research: Capable of analyzing multiple research papers simultaneously.
- Software Engineering and Code Analysis: Enables comprehensive understanding of large repositories without fragmenting function calls.
- Autonomous AI Agents: Supports long-term planning and decision-making in complex tasks.
Scenarios Where 1M Tokens May Be An Overkill
- Customer Support Chatbots: Optimized retrieval is more effective than maintaining an excessively large context.
- Casual Conversations: Most conversational AI interactions do not require extensive memory.
- Real-Time Applications: Longer processing times may make models impractical for real-time decision-making.
Future Considerations and Hybrid Approaches
A 1M token context window is a notable advancement, but future AI models will likely integrate hybrid approaches, such as:
- RAG (Retrieval-Augmented Generation): Ensuring only relevant sections of large documents are processed.
- MoE (Mixture of Experts): Selective computation to optimize efficiency.
- Efficient Attention Mechanisms: Improving speed and reducing computational overhead.
- Memory-Augmented AI: Enabling AI models to retain relevant information without relying solely on long context windows.
Future models will likely balance long-context capabilities with optimized retrieval and efficient attention mechanisms to ensure practical usability.
Conclusion
While the introduction of a 1M token context window represents a significant technological milestone, it is not a universal solution. Instead, it should be seen as one part of a broader strategy that incorporates retrieval mechanisms, efficient attention, and selective computation for optimal AI performance.
Next Steps in AI Development
- How will AI balance retrieval-based knowledge with long-context storage?
- Will 1M-token models become viable for consumer hardware in the future?
- What are the best strategies for improving efficiency in large-context models?
These questions will shape the next spree of AI advancements. The future lies not in merely increasing token limits but in refining how AI processes, retrieves, and retains knowledge efficiently.